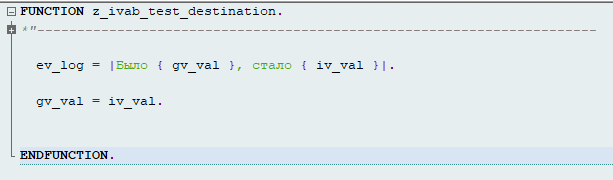
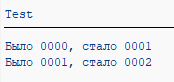
Вот иногда живёшь так, думаешь на автопилоте, что если начал новый LUW то это как портал в новую вселенную:
А вот нифига, LUW может быть и новый, стек вызовов начинается с %_RFC_START, однако определённые в TOP-инклюде глобальные данные группы функций никак не инициализируются:
Вот и получается, что LUW и Internal session это не одно и то же.
Это всё тянется из тех старинных времён, когда SAP работал в терминале и выглядел примерно так:
С тех пор мало что поменялось внутри, экраны устроены та же, всё фиксированной ширины, замкнутый цикл PBO/PAI. Поэтому для значения TRUE используется крестик [X], потому что именно так он отражался на терминале.
На экране пробел от подчёркивания отличить нельзя, поэтому поля содержащие только пробелы и подчёркивания считаются пустыми. И если поле обязательное, то в него нельзя ввести только символ подчёркивания.
Со знаком «равно», видимо, тоже связана какая-то история, могу вообразить, что на некоторых системах ещё не было такой кнопки как F4, или она использовалась для других целей, поэтому для доступа к средству поиска использовалась клавиша =, почему нет.
С восклицательным знаком наверно тоже связана древняя легенда, допускаю что Ctrl+A ещё не изобрели, поэтому разработчики придумали такой «трюк», чтобы проще стирать данные в поле.
*----------------------------------
* (с) Слепаков
*----------------------------------
DO.
Это был тяжелый год
Был он тяжелей, чем тот
Неожиданно нам всем
Много он принес проблем
Но приходит новый год
Он нам счастья принесет
И я верю через год
Дружно скажет наш народ
ENDDO.
Если кратко, то может быть и можно, но всё очень-очень сложно.
Тут вопрос в концепции.
С одной стороны, любая программа ABAP работает только на сервере. SAP GUI работает на компьютере пользователя и отвечает только за показ результата работы и ожидание дальнейших инструкций от пользователя. Пользователь видит результат, нажимает кнопку, SAP GUI передаёт нажатие кнопки на сервер, серверная программа снова отрабатывает и даёт новый результат, отправляет его на просмотр пользователю.
Это круг PAI-PBO, который никогда не прекращается.
BTW, с точки зрения архитектуры SAP GUI — это «тонкий клиент», так как никакая прикладная логика на нём не работает, только красивое отображение и приём-передача информации на сервер и обратно.
С другой стороны, список последних введённых значений хранится только на SAP GUI (то есть на компьютере пользователя), и сервер ничего не знает про это. Так же как и не знает какого цвета кнопки. Вы можете сами включить в SAP GUI любую тему и поменять все цвета, но на работу ABAP это никак не повлияет, и сервер про это никогда не узнает.
С точки зрения ABAP-сервера, нет никакой разницы, выбираете ли вы значение из истории, или вводите его вручную заново, или вставляете из буфера обмена.
На практике существуют некоторые пользовательские функции, когда необходимо взаимодействие ABAP-сервера и SAPGUI-клиента:
Оно реализовано очень нетривиально внутри, можете убедиться.
Если поглядеть в класс CL_GUI_FRONTEND_SERVICES, например в метод CALL_METHOD, то окажется, что ничего просто так сделать не получится.
Вообще большой вопрос — умеет ли SAP GUI отдавать такую информацию или нет, документировано это или нет. В классе не видно ни одного метода, отдалённо напоминающего требуемую функциональность.
Тупик, приехали.
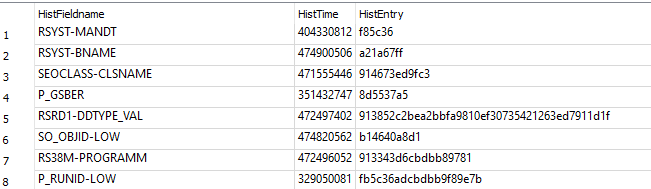
На крайний случай, если очень-очень хочется, чисто теоретически, можно найти на клиенте (компьютере пользователя) файл, куда пишется история, загрузить его в ABAP и распознать.
Этот файл пишется в моём случае в формате SQLite, который неизвестно как разбирать, напрямую в ABAP его анализ невозможен. Ещё неизвестно, что за защита на нём стоит, потому что внутре данные покорябаны:
Тоже приехали.
На моей памяти это задача одна из самых невозможных. Хотя казалось бы…
Снова ничего нового, кажется, но ведущие соскочили на привычные рельсы, у меня было стойкое ощущение дежа-вю. В целом согласен со всеми участниками, но у меня своя правда.
Я в текущих своих условиях вижу один довод «за» — если есть процедура Code review, то я пишу чище.
Кстати, устоявшегося термина на русском языке так и не сложилось. Википедия предлагает сразу четыре варианта:
Просмотр кода, рецензирование кода, обзор кода, ревизия кода
Разработка программных приложений по модулям: FI, FI-AA, CO, MM;
Разработка отчетов и печатных форм;
Внесение изменений в существующие разработки;
Адаптация стандартных программ SAP;
Разработка межсистемных интерфейсов;
Оптимизация программного кода.
Требования:
От 5ти лет опыта в ABAP-программировании;
Опыт отладки, доработки и понимания чужого кода;
Опыт выгрузки в шаблоны Excel, Word, обработка XML;
Использование принципов оптимизации быстродействия ABAP-программ и SQL-запросов;
Знание технологий расширения SAP стандарта (User-Exit, BAdi, OpenFI и др.).
А вот в условиях я кое-за-что зацепился взглядом:
Условия:
Удаленная форма работы;
Полная занятость, полный день;
График работы 5/2, сб и вс — выходные, в пятницу до 15:30;
Посещение офиса в Москве несколько раз в месяц;
Версия SAP – 4.6C;
Версия 4.6С это примерно 2000 год.
Мне так помнится, что когда я начинал карьеру ABAP-разработчика, то у заказчика стояла версия 4.7, которую мигрировали сначала на 5.0, а потом и на 6.0.
В целом, если система стоит и работает с 2000 года по 2022 год, то она проработает и до 9999 года. А вот дальше — уже не получится.
Впрочем, нет, я не готов возвращаться на старый отладчик.
Нарисуй агитационный плакат в советском стиле. В нижней части кадра рука протягивает человеку в косттюме доисторический каменный молоток. Человек на главном переднем плане жестом руки отказывается от этого каменного молотка. По середине плаката находится крупная надпись «НЕТ!».
Этот плакат показывает человека, который отказывается от предложенного каменного молотка. Он демонстрирует, что люди не должны использовать устаревшие инструменты и технологии, а должны использовать современные методы и технологии. Это важное сообщение для всех, кто занимается наукой и технологиями.